vector를 요소로 갖는 벡터를 선언하여 2-dim array를 구현 가능. 이 경우, 각각의 row는 별도의 vector 이므로, n x n 으로 딱 떨어지는 행렬 뿐 아니라 row마다 서로 다른 크기의 column을 가지게 하는 것도 가능.
예제
단, method1 의 경우 column의 크기가 커지는 경우 vector 재할당이 발생해 효율이 떨어질 수 있음. 특히 새로운 row의 추가로 인한 vector 재할당은 단순히 그 row만 영향을 받는게 아니라 전체 row에 대해 재할당이 일어나기 때문에, 각 row 별로 vector 들이 전부 재할당 되어 더욱 심각한 비효율을 초래함.
결과
========================
0 1 2
3 4 5
========================
1 2 3
4 5 6
========================
0 0 0
0 0 0
4월 21, 2016
multi-dimensional vector로 2차원 행렬 구현하기
4월 15, 2016
STL unordered map
associative container. 각 element는 Hash 함수를 통해 bucket이라는 하위 시퀀스로 약하게 정렬됨. bucket 간의 탐색 시간은 constant, bucket 내에서의 탐색 시간은 linear함.
요소를 제거하는 경우 해당 요소의 iterator는 무효화되지만, 그외 다른 iterator는 유효함.
사용법
- key와 element의 std::pair를 element로 가짐
- iterator를 사용한 sequential한 반복 탐색, range 반복 탐색 가능(begin(), end())
- 요소 삽입은 insert(..) 혹은 emplace(..) 사용
- operator[key]를 이용한 random access 가능. 만약 존재하지 않는 key에 접근하는 경우 해당 key를 갖는 새로운 element 생성
- find(key)로 탐색 가능. 반환형은 해당 element의 iterator
- count(key) vs size(): count는 지정된 key를 갖는 element의 수를 반환, size는 map 내의 element 총개수를 반환. unorded_map의 경우 모두 다른 key 값을 갖기 때문에, 해당 key의 element가 있으면 1, 없으면 0 반환
- erase(..): key나 iterator, ranged iterator로 지울 element 선택 가능. 각 경우에 따라 반환형이 달라지는데, key의 경우 지워진 element의 개수, iterator의 경우 지워진 element 중 마지막 element의 iterator를 반환
- clear(): 모든 element의 destructor를 부르고 container에서 drop시킴. size는 0이 됨
예시
references
4월 13, 2016
git rebase -i 사용법
rebase 과정
- txt 파일에 1 2 3 4 5 6 7 작성 후 각각 commit.
- rebase 실행: git rebase HEAD~7 -i
- HEAD 는 어느 commit 까지 rebase 할지를 알려주고 -i 옵션은 interactive 하게 rebase를 실행함을 의미.
- HEAD~n 에서 n은 commit log에서 첫번째 commit까지 rebase하는 경우 1, 2번째까지 rebase하는 경우 2, ... , n번째 commit까지 rebase하는 경우 n이 됨. 즉, 위의 예시에서 "commit 7"이 HEAD~1이 됨
- -i 옵션으로 인해 rebase 대화창이 pop-up
- commands를 입력해 commit 내용 편집, 삭제, 순서 변경 등의 작업을 수행. 메모장을 저장하고 닫으면 commands에 따라 rebase가 수행됨.
- rebase 메시지에서 commit 정렬 순서: 오래된 commit이 위쪽에, 최근에 수행한 commit이 아래쪽으로 정렬됨.
- 병합 순서: commit이 squash 될 때는 위쪽의 commit으로 병합
- rebase 수행 후: "commit 7"
- rebase 수행 후: "commit 4"
- rebase 수행 후: "commit 1"

<text 파일 내용>
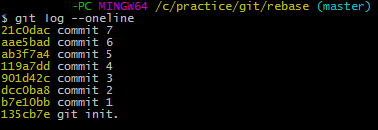
<commit log>
현재 HEAD는 "commit 7"을 가리키고 있음.
 <변경 전 commit>
<변경 전 commit>  <수정 된 commit>
<수정 된 commit> 오래된 commit에 차곡차곡 변경 사항이 쌓임. 위의 예에서는 "commit 2" 가 "commit 1"에 병합. "commit 6" -> "commit 5" -> "commit 4"에 병합.
 <commit log>
<commit log>  <text file contents>
<text file contents> "commit 4"에 "commit 5,6"의 내용이 병합. 위쪽(보다 오래된 commit)에 변경 사항이 누적됨.
 <text file contents>
<text file contents> "commit 1"에 "commit 2"의 내용이 병합. 위쪽(보다 오래된 commit)에 변경 사항이 누적됨.
 <text file contents>
<text file contents> references
Rewriting history4월 05, 2016
operator [][] 구현
operator[][] function은 존재 X
overloading 할 수 있는 여러 종류의 operator function이 있지만, operator [][] function은 존재하지 않음. 다만 직접 [][]의 overloading이 불가능할 뿐이지 간접적인 방법으로는 overloading 가능
operator[][] overloading
operator [][]를 구현하려는 클래스의 operator[]를 overloading 해서 중간에 거쳐가는 객체(임시 클래스)를 리턴하도록 하고, 이 클래스의 operator[]를 오버로딩하면 operator[][]를 구현 가능.
references
피드 구독하기:
글 (Atom)